[JAVA] Disruptor, Multiple Worker Threads 비교
두 가지의 동시성 아키텍쳐(executor thread pool, disruptor)의 성능을 비교하는 영문 기사의 저 호춘쿠키 나름의 번역본 입니다. 오역 댓글로 태클 웰컴 ^^*
우리는 데이터를 풍부하게 이용할 수 있는 밀레니엄 시대에 살고 있다. 매일, 우리는 짧은 시간 안에 복잡한 처리를 필요로 하는 많은양의 데이터를 다루고 있다. 동시에 발생하는 유사하거나 상호 관련된 이벤트들로부터 데이터를 가져오는 것은 우리가 정기적으로 겪어야 하는 프로세스다. 여기서 우리는 복잡한 태스크(task)들을 나누고 그것들을 여러 스레드에서 처리함으로써 짧은 시간 안에 결과물을 내놓는 병렬처리가 필요하다. 병렬로 처리하는 것은 각각의 스레드들에 의해 이벤트들이 처리가 되었을 때의 해당 결과물들의 순서를 보장해야 할 때 오버헤드(overhead)를 유발할 수 있다.
이 기사에서는 위에서의 오버헤드로부터 안전한, 즉, 이벤트 순서를 보장하는 두 가지의 병렬 프로그래밍 모델에 중점을 두고 각각의 퍼포먼스를 리뷰한다. 퍼포먼스 수치들은 molding machine 로부터 센서로 읽어온 데이터 셋을 통해 얻게 되었다. 데이터 셋의 속성은 기계의 번호, timestamp(시간), 데이터를 얻었을 때의 dimension과 reading의 값들을 포함한다(?). 데이터는 파일에서 읽혀지고, 각각의 스레드는 커스터마이징된 "event" 객체를 만드는 task에 할당된다. 객체가 만들어진 후, 각각의 스레드의 결과물은 해당 객체의 시간의 오름차순으로 얻어져야 한다.
Executor Pool With Multiple Queues
첫번째 아키텍처에서는 thread pool을 사용하여 병렬로 task들을 처리할 스레드들 사이에서의 부하를 분산시키는데 사용한다. thread pool을 사용할 때, 우리는 task들이 실행을 끝냈을 때의 순서를 보장할 수 없다. 이벤트들이 병렬로 처리되기 때문에 처리가 되어야 할 스레드에 할당된 이벤트의 실행이 순서대로 수행되지 않는다. 순서를 보장하기 위해서는, 리턴된 결과를 use case에 기반하여 사전에 정의된 기준에 따라 정렬이 되야한다. 스레드로부터 얻어진 각각의 결과는 큐에 published(enqueue)해야 한다.
이러한 Queue들은 개별적으로 정렬되지만 모든 큐 들이 그러하지 않다. 결과들의 마지막 순서를 보장하기 위해서는 분리된(별도의) 스레드가 사용된다. 이 스레드는 각 큐의 헤드를 가져와서 일시적으로 저장하고, 추가적인 processing을 위해 사전에 정의한 기준에 따라 데이터 항목을 정렬하고 release 해준다.
비록 병렬 처리(parallel processing)이 처리 속도를 올리기 위해 수행이 되어도, 병렬 처리를 통해 예상되는 빠른 실행이 응용 프로그램에서 발생하지 않는 정렬 과정에서 bottleneck을 유발할 것이다. 해당 아키텍쳐는 아래에.
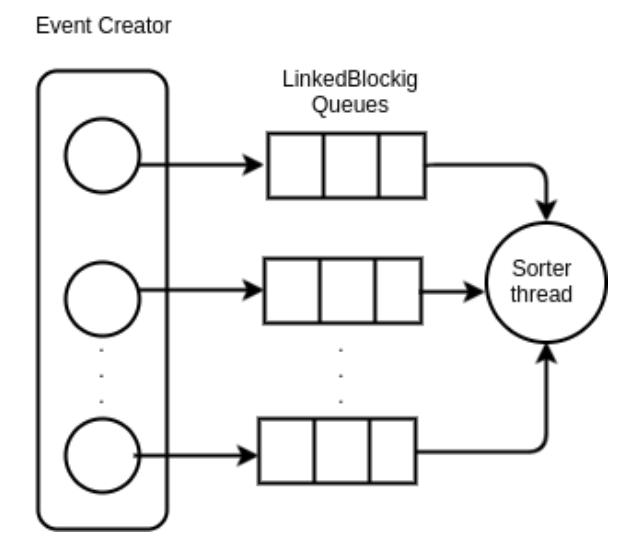
아래에 있는 그림은 thread pool에서 나온 데이터를 저장하고 있는 3개의 큐들이고, released 된 데이터는 시간 순으로 예상이 되어진다. 보다시피 모든 각 큐에 있는 모든 데이터 항목들은 개별적으로 정렬되어있지만, 전체가 그런것은 아니다. 이벤트들의 최종적인 순서를 보장하기 위해서는 추가적인 스레드가 필요하다. 이 스레드는 각 큐의 head를 가져와서, 순서를 보장하기 위해 hold 하고 있다가 가장 짧은 시간에 데이터 항목을 release 해준다.

Parallel Processing Using the Disruptor
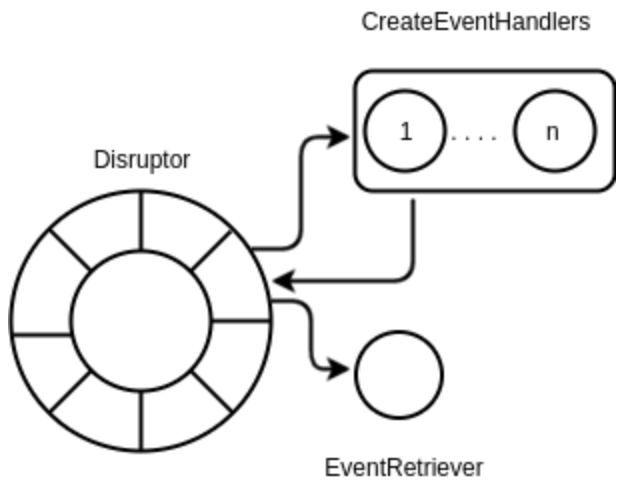
두 번째 아키텍쳐는 Java의 API인 concurrent를 사용하는 Disruptor다. Disruptor는 병렬로 처리될 수 있도록 이벤트를 붙잡고 있는 링버퍼를 메인 데이터 구조로 사용한다. 이벤트가 링 버퍼에 published 되자마자 consumer(혹은, API를 호출하는 이벤트 핸들러들)들은 이벤트를 작동시키고, 병렬로 그것들을 처리한다. disruptor 안에 있는 각각의 이벤트들은 초기화된 이벤트 핸들러에 의해 pick up 되어진다. 즉, 그것들은 multicasted(데이터를 여러 사용자에게 동시에 보내는 것) 된다. 만약 그 이벤트가 오직 하나의 이벤트에 의해 처리가 되어진다면, handler 구현에서 필터링 기준을 지정해야 한다. 이벤트 핸들러의 타입은 이벤트에서 수행 작업에 따라 정의된다.
이벤트 핸들러가 이벤트에서 작동할 수 있는 순서는 이벤트 핸들러 내에 있는 메소드를 사용하여 구체화될 수 있다. 이 순서는 자동적으로 이전 핸들러가 링 버퍼에 저장된 이벤트의 처리를 완료하면서 작동하는 disruptor API에 의해 조정된다.
이전 아키텍쳐에서 경험한 정렬 병목현상을 제거하기 위해서는, 필요한 처리 과정을 수행한 후에 링 버퍼 내 똑같은 위치에 이벤트를 다시 write 하는 이벤트 핸들러에 의해 이벤트들의 순서를 보장할 수 있다.
또 다른 핸들러는 이전 핸들러가 이벤트들을 링 버퍼에 다시 쓴 후에 모든 이벤트를 read 하는 것에 할당이 되어있다.
Executor executor = Executors.newCachedThreadPool();
Disruptor<EventWrapper> disruptor = new Disruptor<>(EventWraper::new, 128, executor);
RingBuffer<EventWrapper> buffer = disruptor.getRingBuffer();
CreateEventHandler[] create = new CreateEventHandler[3];
for(int i = 0; i < 3; i++) {
create[i] = new CreateEventHandler(i, 3, buffer);
}
EventRetriever eventRetriever = new EventRetriever();
disurptor.handleEventsWith(create);
disurptor.after(create).handleEventsWith(eventRetirever);
disruptor.start();위 Disruptor는 버퍼 사이즈가 128인 링 버퍼로 초기화되었다. EventWrapper 은 링 버퍼 내에 저장된 커스텀 객체다. CreateEventHandler 와 EventRetrieve라는 이름의 두 가지 이벤트 핸들러가 사용이 된다. handleEventsWith 메소드는 링 버퍼에 저장된 객체들을 처리해야 하는 이벤트 핸들러의 수를 지정한다. 이벤트에서 작동해야 하는 이벤트 핸들러의 순서를 지정하기 위해서는 after 메소드가 사용된다. 이 메소드는 CreateEventHandler 가 이벤트들을 처리한 직후에만 그 이벤트들을 EventRetriever 가 처리할 수 있게 보장한다.
Publishing to the Ring Buffer
long sequence = buffer.next();
EventWrapper wrap = buffer.get(sequence);
wrap.setData(data);
wrap.setTime(System.currentTimeMillis());
buffer.publish(sequence);링 버퍼에 publish 하기에 앞서, 링 버퍼 안에서 이벤트가 publish 되어야 할 다음 위치는 버퍼의 next 메소드를 호출함으로써 얻을 수 있다. EventWrapper 객체가 만들어지고 링 버퍼로부터 얻은 위치에 publish 된다.
Implementing an Event Handler
이벤트 핸들러는 아래 코드와 같이 구현된다.
public class CreateEventHandler implements EventHandler<EventWrapper> {
private final long ID;
private final long NUM;
private RingBuffer<EventWrapper> buffer;
public CreateEventHandler(int ID, int num, RingBuffer<EventWrapper> buffer) {
this.ID = ID;
this.NUM = num;
this.buffer = buffer;
}
@Override
public void onEvent(EventWrapper eventWrapper, long sequence, boolean b) throws Exception {
if(!evetWrapper.isLast()) {
String[] data = eventWrapper.getData();
int partition = Integer.parseInt(data[2].split("_")[1]);
if(partition % NUM == ID) {
// 핸들러에 의해 수행될 로직 구현
buffer.publish(sequence);
}
}
}
}EventHandler 인터페이스 안에 있는 onEvent 메소드는 링 버퍼에서 나온 이벤트 위에 있는 핸들러에 의해 수행될 로직을 구체화하기 위해 override 되어진다(overridden). 모든 스레드에 의해 모든 이벤트를 처리하지 않도록 이벤트들을 필터링하기 위해서는 각각의 핸들러에 할당된 ID 값에 기반을 둔 파티션 번호들을 사용한다. 그 시퀀스(파티션 번호들을 말하는 듯, sequence)는 링 버퍼 안에서 처리되어진 이벤트들의 위치다. 작업들이 수행된 후에, 해당 이벤트는 링 버퍼의 publish 메소드를 호출함으로써 똑같은 위치에 다시 published 된다.
아래 표는 스레드/이벤트 핸들러의 수에 따른 두 가지 아키텍쳐들의 throughput(처리량)과 latency(대기 시간)을 요약한 것이다.


여기서 우리는 disruptor-based 아키텍쳐가 executor pool-based 아키텍쳐보다 latency가 훨씬 더 낫다는 것을 알 수 있다. 하지만 throughput은 executor-based 아키텍쳐가 더 낫다.
결론
첫 번째 아키텍쳐(Executor Pool with Multiple Queues)는 disruptor 아키텍쳐와 비교했을 때 throughput이 더 높지만 그 차이는 그다지 크지 않다는 것을 알 수 있다. 반면에, disruptor-based 아키텍쳐는 executor-thread-pool-based 를 구현한것과 비교했을 때 latency가 현저하게 낮다는 것을 보였다. disruptor-based 모델의 낮은 레이턴시 이유는 lock-free algorithms을 광범위하게 사용하기 때문이다.
원문 : https://dzone.com/articles/performance-evaluation-disruptor-with-parallel-con
'개발 지식 > Java' 카테고리의 다른 글
| [JAVA] JAR WAR 차이 (0) | 2020.06.27 |
|---|---|
| [Java] ParameterizedPreparedStatementSetter setValues해야 하는 컬럼이 많다면? (0) | 2020.06.16 |
| [Java] Producer - Consumer 패턴 구조 (0) | 2020.05.03 |
| [JAVA] JDBC, JPA/Hibernate, MyBatis 차이점 (0) | 2020.04.21 |
| [Java] Jetty 란? (0) | 2020.04.06 |

